
In Data, Why is our Daily Driver an F1 Racecar?
Most data teams build a custom racecar for their analytics—not because they want to, but because that's just how the modern data stack works.

Most data teams build a custom racecar for their analytics—not because they want to, but because that's just how the modern data stack works. You pick Snowflake, BigQuery, or Databricks as your engine and build the rest of the car around it. Whether you're using Fivetran or Airbyte, dbt or Coalesce, you've got to do a ton of custom work to get this car running. But hey, this part of the job is a blast! Teams love getting the budget to design and build a data platform from scratch.
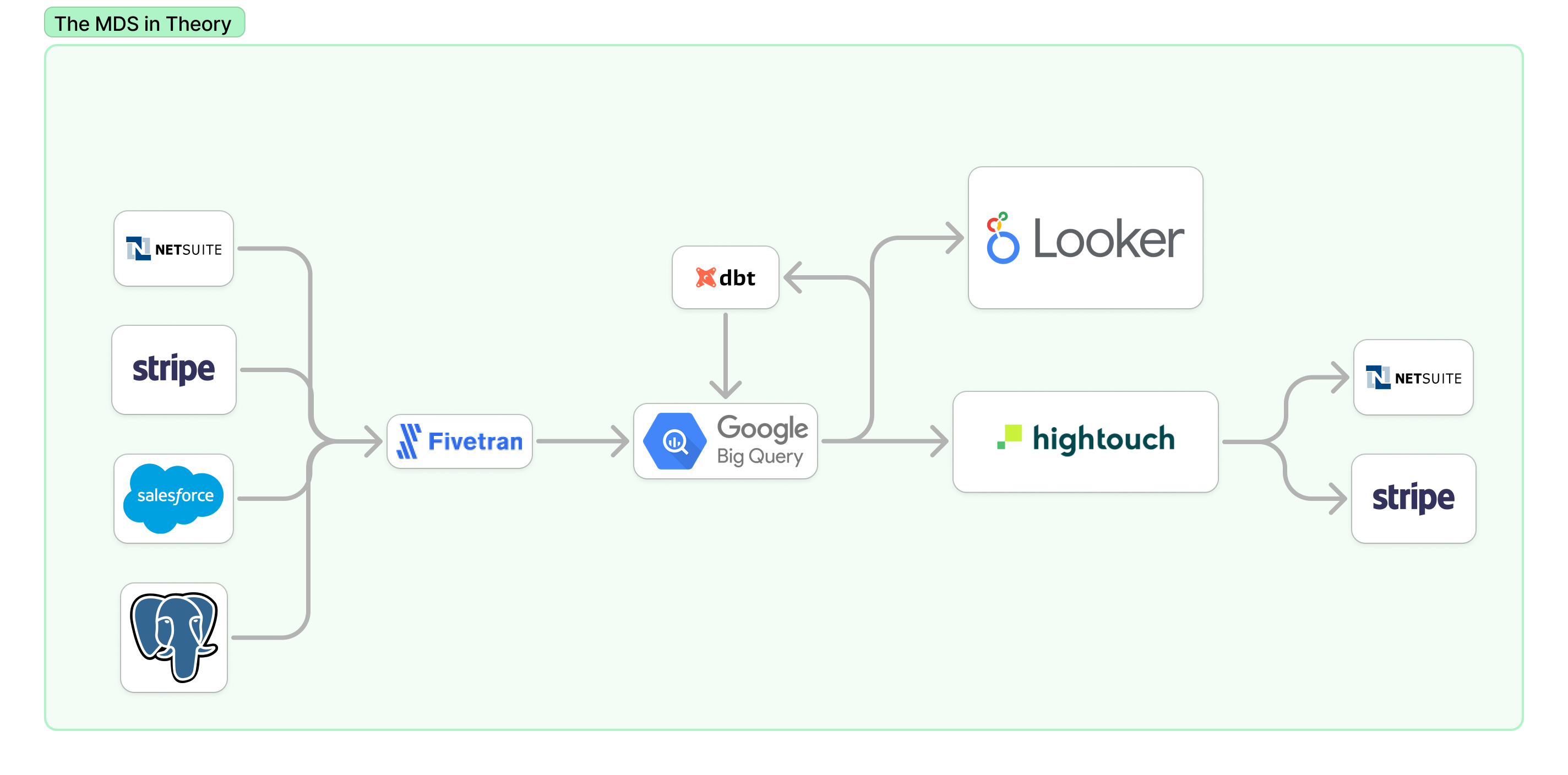
The issue is that as the company scales, the car gets more complex. You start adding more features to handle all the new requests and edge cases. Before you know it, you've got new dashboards, a reverse ETL tool thrown into the mix, and even a catalogue to tie it all together. You and your team get busy building foundational data models that the analysts then run with. Even though these models pull data from standard data sources such as Quickbooks, Stripe, ERPs, etc., the models are customized to your organization and often overfitted with business logic.
All these tools are beneficial and serve a purpose, but the complexity grows with them. To make matters worse, while your core team does most of the work occasionally, you let a product team member create a few dashboards and write some queries in the name "self-service." As a result, context is added, or assumptions are made that don't fit your team's standard model. This mess lives in dbt, Airlow, as the core logic is stored there. However, this can expand into BI tools like Looker or upstream integration tools. This customization and maintenance is a huge drag on teams. A dbt labs survey suggests teams spend 26% of their week fixing and maintaining their infrastructure. The point is it gets complicated quickly!

Before you know it, the models start to break down, and the custom racecar you and the team built is in the shop and takes forever to fix. Why? It's for a multitude of reasons. A collection of people (some not at your company anymore) have written hundreds of models; you have ten workloads calculating similar things in slightly different ways hooked up to ‘core sources of truth.’ A lot of times, dbt models are added without rules or assumptions. You start to see duplications, models not referencing the correct upstream table, and models running hourly where the data is only updated every 6 hours.
The outcome? It's been 2-5 years with the MDS, and your costs are way higher than you predicted; your pipelines are fragile and constantly breaking, and logic is siloed across many tools. This is a reality for data teams.
So how do you fix it? This is a question a lot of data teams are asking themselves. From the teams we have spoken to, there are a few outcomes.
They do nothing and hope it’ll figure itself out one day. (Spoiler: it won’t).
They commission a team of 1 or 2 engineers to focus on this project. They spend 6-9 months on it and are pulled from projects.
They do the opposite and commission 1-2 to focus on new work while the rest of the team is set on fixing their foundation. This is a costly outcome.
They use Artemis.
Each option is time-consuming, expensive, and has a huge opportunity cost. When trying to solve these issues manually, you discover how hard it is to search for issues across the stack while holding the entire platform's design in one or two people's heads. It’s a large reason why this work doesn’t get done.
Data platforms are held together with duct tape, which is the nature of the beast. Still, teams can invest in tooling that helps maintain those systems so they can focus on delivering value for the business instead of constantly repairing what’s broken.
What is Artemis?
Artemis is an end-to-end data platform mechanic. Our platform monitors your stack, finds issues within your warehouse, dbt models, and BI tools, and then auto-resolves them, so all you need to do is approve insights and merge PRs. The platform does all the research and highlights where you can cut bloat, improve performance and save warehouse costs.
We tune your data platform to be a lean, fast, and smooth machine so your engine is humming, and you fly by your OKRs. The average team approves 120 insights, merges 60 PRs and saves 25 hours a week!
If you want to optimize costs or cut dbt bloat, reach out!